![]()
![]()
The oldest and simplest MST algorithm was discovered by Boruvka in 1926. The Boruvka's algorithm was rediscovered by Choquet in 1938; again by Florek, Lukaziewicz, Perkal, Stienhaus, and Zubrzycki in 1951; and again by Sollin in early 1960's. The next oldest MST algorithm was first described by the Polish mathematician Vojtech Jarnik in a 1929 letter to Boruvka. The algorithm was independently rediscovered by Kruskal in 1956, by Prim in 1957, by Loberman and Weinberger in 1957, and finally by Dijkstra in 1958. This algorithm is (inappropriately) called Prim's algorithm, or sometimes (even more inappropriately) called 'the Prim/Dijkstra algorithm'. The basic idea of the Jarnik's algorithm is very simple: find A's safe edge and keep it (i.e. add it to the set A).
Overall Strategy
Like Kruskal's algorithm, Jarnik's algorithm, as described in CLRS, is based on a generic minimum spanning tree algorithm. The main idea of Jarnik's algorithm is similar to that of Dijkstra's algorithm for finding shortest path in a given graph. The Jarnik's algorithm has the property that the edges in the set A always form a single tree. We begin with some vertex v in a given graph G =(V, E), defining the initial set of vertices A. Then, in each iteration, we choose a minimum-weight edge (u, v), connecting a vertex v in the set A to the vertex u outside of set A. Then vertex u is brought in to A. This process is repeated until a spanning tree is formed. Like Kruskal's algorithm, here too, the important fact about MSTs is that we always choose the smallest-weight edge joining a vertex inside set A to the one outside the set A. The implication of this fact is that it adds only edges that are safe for A; therefore when the Jarnik's algorithm terminates, the edges in set A form a minimum spanning tree, MST.
Details
The Jarnik's algorithm builds one tree, so A is always a tree.
It starts from an arbitrary "root" r.
At each step, find a light edge crossing cut (VA, V − VA), where VA = vertices that A is incident on. Add this edge to A.
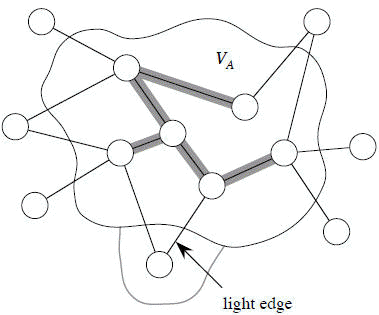
Note that the edges of A are shaded.
Now the question is how to find the light edge quickly?
Use a priority queue Q:
Each object is a vertex in V − VA.
Key of v is minimum weight of any edge (u, v), where u ∈ VA.
Then the vertex returned by EXTRACT-MIN is v such that there exists u ∈ VA and (u, v) is light edge crossing (VA, V − VA).
Key of v is ∞ if v is not adjacent to any vertices in VA.
The edges of A will form a rooted tree with root r :
Algorithm
Choose a node and build a tree from there selecting at every stage the shortest available edge that can extend the tree to an additional node.
JARNIK(V, E, w, r )
Q ← { }
for each u in V
do key[u] ← ∞
π[u] ← NIL
INSERT(Q, u)
DECREASE-KEY(Q, r, 0) ▷ key[r ] ← 0
while Q is not empty
do u ← EXTRACT-MIN(Q)
for each v in Adj[u]
do if v in Q
and w(u, v) < key[v]
then π[v] ← u
DECREASE-KEY(Q, v, w(u, v))
Illustrative Example
Do example from CLRS page 571.
Analysis
The performance of Jarnik's algorithm depends on how the priority queue is implemented:
In depth Complexity Analysis of Jarnik's Algorithm
But before we start the analysis, recall some definitions from graph theory. Sparse graphs are those for which |E| is much less than |V|2 i.e., |E| << |V|2, we preferred the adjacency-list representation of the graph in this case. On the other hand, dense graphs are those for which |E| is close to |V|2 i.e., |E| ≈ ||V|2. In this case, we like to represent graph with adjacency-matrix representation.
As we have mentioned above, the performance of Jarnik's algorithm depends of how we choose to implement the priority queue Q.
When a Q is implemented as a binary heap
We can use the BULID_HEAP procedure to perform the
initialization in lines 1-4 in O(|V|) time. The while-loop in
lines 6-11 is executed |V| times, and since each EXTRACT_MIN
operation takes O(lg|V|) time, the total time for all calls to
EXTRACT_MIN operation is O(|V| lg |V|). The for-loop in lines
8-11 is executed O(|E|) times altogether, since the sum of the
lengths of all adjacency lists is 2|E|. Within the for-loop, the
test for membership in Q in line 9 can be implemented in
constant time by keeping a bit for each vertex that tells
whether or not it is in Q, and updating the bit when the vertex
is removed from Q. The assignment in line 11 involves an
implicit DECREASE_KEY operation on the heap, which takes O(lg |V|)
time with a binary heap. Thus, the total time for Jarnik's
algorithm using a binary heap is O(|V| lg|V| + |E| lg |V|).
When Q is implemented as a Fibonacci heap
In this case, the performance of the DECREASE_KEY operation
implicitly called in line 11 will be improved. Instead of taking
O(lg|V|) time, with a Fibonacci heap of |V| elements, the
DECREASE_KEY operation will take O(1) amortized time. With a
Fibonacci heap, an EXTRACT_MIN operation takes O(lg |V|)
amortized time. Therefore, the total time for Jarnik's algorithm
using a Fibonacci heap to implement the priority queue Q is
O(|V| lg |V| + |E|).
When graph G = (V, E) is sparse i.e., |E| =
Θ(|V|)
From above description, it can be seen that both versions of
Jarnik's algorithm will have the running time O(|V| lg |V|).
Therefore, the Fibonacci-heap implementation will not make
Jarnik's algorithm asymptotically faster for sparse graph.
When graph G is dense, i.e., |E| = Θ(|V|)
From above description, we can see that Jarnik's algorithm with
the binary heap will take |V|2 lg |V| time whereas
Jarnik's
algorithm with Fibonacci-heap will take |V|2. Therefore, the
Fibonacci-heap implementation does not make Jarnik's algorithm
asymptotically faster for dense graphs.
Comparing the time complexities of the two versions of Jarnik's algorithms, mentioned in (a) and (b), we can see that |E| is greater than |V|, the Jarnik's algorithm with the Fibonacci-heap implementation will be asymptotically faster than the one with the binary-heap implementation.
The time taken by the Jarnik's algorithm is determined by the speed of the queue operations. With the queue implemented as a Fibonacci heap, it takes O(E + V lg V) time.
Since the keys in the priority queue are edge weights, it might be possible to implement the queue even more efficiently when there are restrictions on the possible edge weights.
We can improve the running time of Jarnik's algorithm if W is a constant by
implementing the queue as an array Q[0 . .W + 1] (using the W + 1 slot for key =
∞), where each slot holds a doubly linked list of vertices with that weight as
their key. Then EXTRACT-MIN takes only O(W) = O(1) time (just scan for the first
nonempty slot), and DECREASE-KEY takes only O(1) time (just remove the vertex
from the list its in and insert it at the front of the list indexed by the new
key). This gives a total running time of O(E), which is the best possible
asymptotic time (since Ω(E) edges must be processed).
However, if the range of edge weights is 1 to |V|, then EXTRACT-MIN takes Θ(V) time with this data structure. So the total time spent doing EXTRACT-MIN
is Θ(V2), slowing the algorithm to Θ(E + V2) = (V2). In this case, it is better
to keep the Fibonacci-heap priority queue, which gave the Θ(E + V lg V) time.
There are data structures not in the CLRS that yield better running times:
The van Emde Boas data structure (mentioned in the chapter notes for Chapter 6 and the introduction to Part V) gives an upper bound of O(E + V lg lg V) time for Jarnik's algorithm.
A redistributive heap (used in the single-source shortest-paths algorithm of Ahuja, Mehlhorn, Orlin, and Tarjan, and mentioned in the chapter notes for Chapter 24) gives an upper bound of O(E + V √lg V) for Jarnik's algorithm.
Jarnik's Algorithm with Adjacency Matrix
Now we describe the Jarnik's algorithm when the graph G = (V, E) is represented as an adjacency matrix. Instead of heap structure, we'll use an array to store the key of each node.
1. A ← V[G]
▷ Array
2. for each vertex u in Q
3. do key [u] ← ∞
4. key [r] ← 0
5. π[r] ← NIL
6. while array A is empty
7. do scan over A find the node u with smallest key, and remove it from array A
8. for each vertex v in Adj[u]
9. if v is in A and w[u, v] <
key[v]
10. then π[v] ← u
11. key[v] ← w[u, v]
Analysis
For-loop (line 8-11) takes O(deg[u]) since line 10 and 11 take constant time.
Due to scanning whole array A, line 7 takes O(V) time and lines 1-5, clearly
take (V).
Therefore, the while-loop (lines 6-11) needs
Ο(∑u(V + deg[u])) = Ο(V2 + E)
= Ο(V2)
![]()
![]()
Dated: February 9, 2010.