![]()
Despite of the fact that a thread must execute in process, the process and
its associated threads are different concept. Processes are used to group
resources together and threads are the entities scheduled for execution on the
CPU.
A thread is a single sequence stream
within in a process. Because threads have some of the properties of processes,
they are sometimes called lightweight processes. In a process, threads allow
multiple executions of streams. In many respect, threads are popular way to improve
application through parallelism. The CPU switches rapidly back and forth among
the threads giving illusion that the threads are running in parallel. Like a
traditional process i.e., process with one thread, a thread can be in any of
several states (Running, Blocked, Ready or Terminated). Each thread has its own
stack. Since thread will generally call different procedures and thus a
different execution history. This is why thread needs its own stack. An operating system that has thread facility,
the basic unit of CPU utilization is a thread. A thread has or consists of a program counter (PC), a register set, and
a stack space. Threads are not independent of one other like processes as a
result threads shares with other threads their code section, data section, OS
resources also known as task, such as open files and signals.
As we mentioned earlier that in many respect threads operate in the same way as that of processes. Some of the similarities and differences are:
Similarities
Differences
Following are some reasons why we use threads in designing operating systems.
Threads are cheap in the sense that
But this cheapness does not come free - the biggest drawback is that there is no protection between threads.
User-level threads implement in user-level libraries, rather than via systems calls, so thread switching does not need to call operating system and to cause interrupt to the kernel. In fact, the kernel knows nothing about user-level threads and manages them as if they were single-threaded processes.
Advantages:
The most obvious advantage of this technique is that a user-level threads package can be implemented on an Operating System that does not support threads. Some other advantages are
Disadvantages:
In this method, the kernel knows about and manages the threads. No runtime
system is needed in this case. Instead of thread table in each process, the
kernel has a thread table that keeps track of all threads in the system. In
addition, the kernel also maintains the traditional process table to keep track
of processes. Operating Systems kernel provides system call to create and manage threads.
The implementation of general structure of kernel-level thread is
<DIAGRAM>
Advantages:
Disadvantages:
A proxy server satisfying the requests for a number of computers on a LAN would be benefited by a multi-threaded process. In general, any program that has to do more than one task at a time could benefit from multitasking. For example, a program that reads input, process it, and outputs could have three threads, one for each task.
Any sequential process that cannot be divided into parallel task will not benefit from thread, as they would block until the previous one completes. For example, a program that displays the time of the day would not benefit from multiple threads.
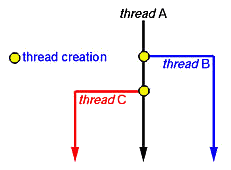
When a new thread is created it shares its code section, data section and operating system resources like open files with other threads. But it is allocated its own stack, register set and a program counter.
The creation of a new process differs from that of a thread mainly in the fact that all the shared resources of a thread are needed explicitly for each process. So though two processes may be running the same piece of code they need to have their own copy of the code in the main memory to be able to run. Two processes also do not share other resources with each other. This makes the creation of a new process very costly compared to that of a new thread.
To give each process on a multiprogrammed machine a fair share of the CPU, a hardware clock generates interrupts periodically. This allows the operating system to schedule all processes in main memory (using scheduling algorithm) to run on the CPU at equal intervals. Each time a clock interrupt occurs, the interrupt handler checks how much time the current running process has used. If it has used up its entire time slice, then the CPU scheduling algorithm (in kernel) picks a different process to run. Each switch of the CPU from one process to another is called a context switch.
In a multiprogrammed uniprocessor computing system, context switches occur frequently enough that all processes appear to be running concurrently. If a process has more than one thread, the Operating System can use the context switching technique to schedule the threads so they appear to execute in parallel. This is the case if threads are implemented at the kernel level. Threads can also be implemented entirely at the user level in run-time libraries. Since in this case no thread scheduling is provided by the Operating System, it is the responsibility of the programmer to yield the CPU frequently enough in each thread so all threads in the process can make progress.
The threads share a lot of resources with other peer threads belonging to the same process. So a context switch among threads for the same process is easy. It involves switch of register set, the program counter and the stack. It is relatively easy for the kernel to accomplished this task.
Context switches among processes are expensive. Before a process can be switched its process control block (PCB) must be saved by the operating system. The PCB consists of the following information:
When the PCB of the currently executing process is saved the operating system
loads the PCB of the next process that has to be run on CPU. This is a heavy
task and it takes a lot of time.
![]()
![]()